On Substitution Ciphers
The Basics
 One of the first “real” programs I ever wrote would encrypt a message
using a substitution cipher and (more impressively) decrypt an encoded message without knowing the
encryption key. Perhaps the first thing I had to come up with was an algorithm to take a cipher key
that was used to encode a message, and transform it so that it could then be used do decode the
ciphertext back into plaintext. I was aware of ROT-13’s property that if applied once to the
plaintext, and again to the output ciphertext, it would yield the original plaintext. That is,
ROT-13 is its own inverse. However, this is not the case for all possible keys, so I needed to find
a more general algorithm.
One of the first “real” programs I ever wrote would encrypt a message
using a substitution cipher and (more impressively) decrypt an encoded message without knowing the
encryption key. Perhaps the first thing I had to come up with was an algorithm to take a cipher key
that was used to encode a message, and transform it so that it could then be used do decode the
ciphertext back into plaintext. I was aware of ROT-13’s property that if applied once to the
plaintext, and again to the output ciphertext, it would yield the original plaintext. That is,
ROT-13 is its own inverse. However, this is not the case for all possible keys, so I needed to find
a more general algorithm.
Before I jump right in, I will give a quick refresher on some terms and properties of substitution ciphers. Let us continue with the ROT-13 example. ROT-13 means “take the alphabet and rotate it 13 steps”, so now A (originally at position 1) is in the 13 + 1 = 14th spot (where M usually lives), B (originally at position 2) is in the 13 + 2 = 15th spot, and so on. Once we get to N at position 14, there is a problem: 14 + 13 = 27, and there are only 26 letters in the alphabet, so we wrap around to the beginning. At the end we are left with our new key:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
NOPQRSTUVWXYZABCDEFGHIJKLM
This tells us that A becomes N, B becomes O, etc. Let’s use this to encode a message.
WE ARE DISCOVERED. FLEE AT ONCE.
JR NER QVFPBIRERQ. SYRR NG BAPR.
If one wishes to decode the “secret” message (also called ciphertext), it quickly becomes apparent that using ROT-13 a second time will give the original (plaintext) message: . An important fact to note is that not only does , but also (or more succinctly ), and indeed this is true for all letters in ROT-13. Mathematically, if is our plaintext, is our ciphertext, and is the ROT-13 function, then and
The Rabbit Hole
Most keys, especially randomly generated keys, are not thier own inverse, and so an algorithm is needed to find a key that will undo the original. I was quite proud of my self all those years ago in my high school CS class when I found the solution using some scratch paper, an excel sheet, and no googling whatsoever. As it happens I am still proud of my past self for that one. The algorithm is as follows:
Let be the key used to encode the message, , and let be the inverse key, which when applied to the ciphertext, gives .
- Look at the nth letter in
- Find the normal position of that letter in the alphabet
- Go to that position in , and set it to the nth letter of the alphabet
Implemented in c++:
1std::string invert(std::string key){
2 std::string inv = empty_key();
3 for (int i = 0; i < 26; i++){
4 inv[key[i] - 'A'] = i + 'A';
5 }
6 return inv;
7}
Which is, in my opinion, a fairly elegant solution. However, it left me wondering if for an arbitrary key, applied repeatedly enough times, the message would eventually come back around to the plaintext.
As a test, I decided to use the key QWERTYUIOPASDFGHJKLZXCVBNM and apply it to the top secret
message, ABCDEFGHIJKLMNOPQRSTUVWXYZ (we can’t risk those communists learning too much about our
alphabet). The resultant ciphertext, somewhat expectedly, was then QWERTYUIOPASDFGHJKLZXCVBNM,
then, encoding the new ciphertext with the same key again, the result was
JVTKZNXOGHQLRYUIPASMBECWFD and after 42 (of course) iterations it was back to
ABCDEFGHIJKLMNOPQRSTUVWXYZi. If
is the function that applies this key to a message
, then
. Let us call this property a key’s period. To better see any
hidden patterns, I whipped up a quick spreadsheet to perform
the substitution and highlight any time a letter got back to its correct position.
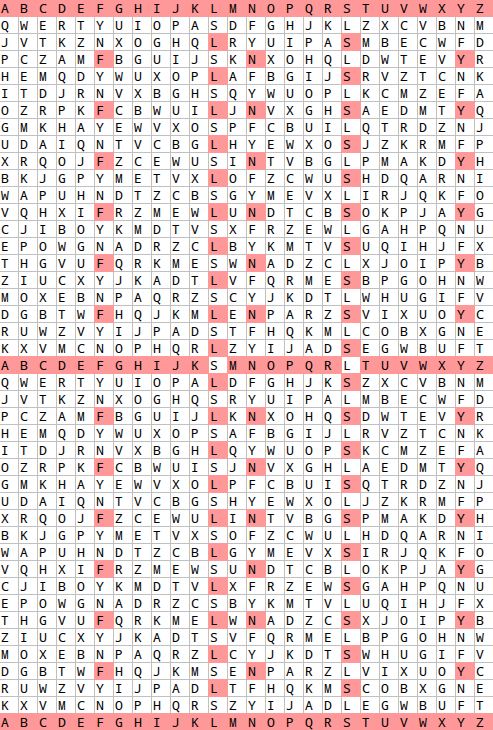
Clearly, there are 3 distinct cycles here: L maps to S, which maps back to L, then F maps to Y which maps to N, and back to F, and then a much longer one.
I will use the following notation to represent a cycle:
Sticking with vector-like notation, the magnitude (or length) of a cycle can be denoted . To find when cycles of different lengths align (equivalent to finding the period of a key), we take the least common multiple of all of the lengths, and indeed .
Integer Partitions and Landau’s Function
Once I had found what determines the period of a key, the next step was to find the maximum possible period of a key. To do so, we must lay down some rules about keys and their cycles.
- All cycles in some key must not share values.
- The sum of the lengths of all cycles must be the length of the alphabet. If we let be the full alphabet, then
- (Optional) Cycles cannot have a length of 1. If this requirement is not taken, then a letter maps to itself. This is not inherently a problem, but you generally do not want a letter to never be encrypted. At least, not in something so simple as a substitution cipher.
Now that there are rules in place, we want to select our cycles such that we maximize the value of . The least common multiple function is greatest when its inputs share the fewest factors. Realizing this, we want to select cycle lengths of prime numbers if possible, and if we must select composite lengths, they should not share factors with any of the other cycles.
Fairly quickly, I found the primes 3, 5, 7, and 11, with a sum of 26 and lcm (and product) of 1155. This seemed like a promising result, but I felt like some extra research was needed in case I had overlooked something simple. After a bit of googling, I found Landau’s Function (A000793) which gives the largest lcm of all partitions of some integer n. That is, given all the ways to add a set of integers together to reach the integer n, landau’s function tells us the largest least common multiple of any of those sets of integers. Though it was exactly what I was looking for, I immediately ran into a problem: Landau’s function , and though I am admittedly not the worlds greatest recreational mathematician, last I checked I was pretty sure that 1260 does not actually equal 1155.
Somewhat surprisingly, it was not so easy to find the specific partitions that yield the values for landau’s function anywhere online, so I had to write a program to do it for me. The first and most involved step is to write a function that takes an integer as input and returns all partitions of that integer. I approched this problem recursively using dynamic programming:
1def partition(n, remember={}):
2 """returns a set of tuples, where each tuple
3 is one partition of the given integer."""
4 if n not in remember:
5 parts = {(n,)}
6 for x in range(1, n):
7 # partition the smaller number and remember the result
8 partition(x, remember)
9 partition(n - x, remember)
10 for r in remember[n-x]:
11 parts.add(tuple(sorted((x,) + r)))
12 remember.update({n : parts})
13 return remember[n]
The parameter n is the integer we wish to partition, and the optional parameter remember is an empty dictionary. As the program runs, it finds the partitions of smaller numbers, and remembers the result. For example, if we are calculating the partitions of the number 10, but already know all the partitions of the smaller numbers then we know that the partitions of ten are 1 + 9 as well as 1 + every partition of 9, 2 + 8 as well as 2 + every partition of 8, and so on.
Finding the least common multiple is relatively trivial. Wikipedia has a great article on The Euclidean Algorithm.
1def gcd(a, b):
2 while b is not 0:
3 a, b = b, a % b
4 return a
5
6def lcm(l):
7 if len(l) == 1:
8 return l[0]
9 a = l[0]
10 for i in range(1, len(l)):
11 a = (a * l[i])//gcd(a, l[i])
12 return a
All that remains to calculate the value of Landau’s function is to iterate over all partitions of a number and find all the ones that share a maximum value.
1def landau(n):
2 parts = partition(n)
3 record = 0;
4 winners = []
5 for part in parts:
6 l = lcm(list(part))
7 if l > record:
8 record = l
9 winners = [part]
10 elif l == record:
11 winners.append(part)
12 print(n, record, winners, sep=';')
As it turns out, rule 3, is what was holding me back. If cycle lenghts of one are allowed, then the partition (9 7 5 4 1) takes the cake with an lcm of 1260. However, I was happy to find that imposing rule 3 on my program gave the result (11 7 5 3) - exactly what I came up with originally. As an interesting side note, I also tried to make a list of all Landau partitions up to 100. My program did quite well up until 91, at which point my 16G of ram was not enough. I then rewrote the code in c++, made it iterative instead of recursive, and managed to reach 100 (however I forgot to account for the fact that several partitions may have the same lcm). Here are the results:
landau.txt landau-greater-than-one.txt
What Did We Learn?
I suppose we learned how to make a substitution cipher key that takes a maximal number of repeated applications to a message to return to the original message. Once we choose the cycle lengths for our key, all we have to do is take each chunk of letters and rotate them by one. Here is a trivial key of period 1155 and 4 cycles:
[BCAEFGHDJKLMNOIQRSTUVWXYZP]
And here is a trivial key of period 1260 with 5 cycles:
[ACDEBGHIJFLMNOPQKSTUVWXYZR]
Both of these keys can be found in the spreadsheet I mentioned earlier, and any key can be placed in row 2 to examine any patterns. For a bit of extra fun, I decided to write some code to determine the period of a given key without needing a human to spot the patterns. cycles.cpp If you wish to run my cycles program yourself, I have only tried compiling it using g++:
$ g++ -std=c++14 cycles.cpp -o cycles
Cycles takes 1 command line argument - the key to be examined:
The key [BCAEFGHDJKLMNOIQRSTUVWXYZP] has the following 4 cycles:
Cycle 1 (Length 3) : ABC
Cycle 2 (Length 5) : DEFGH
Cycle 3 (Length 7) : IJKLMNO
Cycle 4 (Length 11) : PQRSTUVWXYZ
and a total period of 1155.
All in all this was a pretty fun little excursion through some interesting math. I don’t know what anyone will ever make of what I’ve found here, but hopefully it will lead to even more interesting topics in the future.